問題詳情
34 在關聯式資料庫中,一個關係(relation)可以用一個二維表格代表,每一列代表某筆資料(a tuple)
,而每 一欄代表資料的某種屬性(an attribute) 。若設計以下的關聯式資料庫(表一)來記錄一個公司的員工資訊:
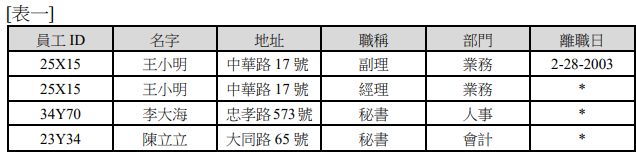
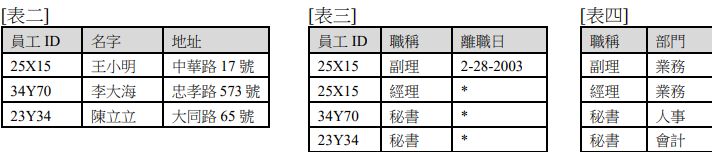
(A)新資料庫無法查出某個員工在公司曾擔任的工作,但原資料庫可以
(B)新資料庫無法查出某個員工在公司工作多久了,但原資料庫可以
(C)新資料庫無法查出某個員工所屬的部門,但原資料庫可以
(D)新資料庫無法查出不同部門的相同工作(如秘書)的人,是住那些地方,但原資料庫可以
參考答案
用户評論
【Show-ping Wan】評論
各位好,以下若有錯誤歡迎指教:要解本題其實先要注意3點:1.主鍵(PK)因唯一性和最小性,每張表必定有一個或一組不會重複的屬性於每筆值組(tuple)中,所以假設[表二]PK為員工ID ,[表三]PK為員工ID+職稱 ,[表四]PK為職稱+部門。2.[表二]與[表三]是1對N關係[表二]PK被[表三]當FK參考; [表三]與[表四]是M對N,例如:[表三]( 34Y70 ,秘書,*)會JOIN[表四](秘書,人事)+[表四](秘書,會計),所以兩表間產生所有可能組合的[新表],形成1:N:1的新關係,並以[表三]與[表四]的PK作為[新表]的PK兼當FK。3. [表一]被切成3張小表格後,[表二],[表三],[表四]預設以full outer join重新連結。而根據1. 2. 3.所述,(A)(B)(C)(D)將分別如以下情形:(A),(B)之情況: [表二]與[表三]是1對N關係,能直接以[表二]中特定屬性值為條件找出[表三]中對應值組(tuple)中的屬性值;所以(A),(B)論述錯誤。(C)之情況: [表三]與[表四]因M對N的關係,[新表]值組(tuple)為所有可能組合,例如 [新表]屬性(員工,職稱,職稱,部門)其中值組(34Y70 ,秘書,秘書,人事) (34Y70 ,秘書,秘書,會計)(23Y34 ,秘書,秘書,人事)(23Y34 ,秘書,秘書,會計);造成查出不正確答案,例如以 部門='人事' 為條件找員工 則可能顯示 '李大海' 與 '陳立立'(部門='會計' 亦同);所以(C)確實無法如[表一]查詢結果,論述正確。(D)之情況: 要問的其實是找出公司中所有當 '秘書' 的人的地址,所以上述[新表]值組(tuple)中以若以 職稱='秘書' / 職稱='秘書'+部門='人事'/ 職稱='秘書'+部門='會計'皆能得出所有當過 '秘書' 的人的地址,只是答查詢結果會重複,可用DISTICT處理;所以(D)論述錯誤。